1. Introducción a la especialización
La dificultad de la presente especialización está catalogada como de nivel intermedio, ya que requiere que poseamos cierta familiaridad con algunos conceptos de programación (en Python fundamentalmente) y estadística. No obstante, siempre podemos optar por complementar los cinco cursos con los materiales necesarios que nos permitan seguir el ritmo de las explicaciones (documentación, tutoriales, libros…).
Python ha sido el lenguaje de programación escogido porque:
- es fácil de aprender, destacando por la gran legibilidad de su código;
- cuenta con cientos de librerías disponibles para desarrollar las tareas más diversas; y
- posee potentes módulos para trabajar en las tareas propias de la Ciencia de Datos (el ecosistema SciPy).
El primer curso de la especialización, Introduction to Data Science in Python, está compuesto por los siguientes cuatro módulos:
- Prerrequisitos de Python.
- La librería Pandas.
- Consultas (”querying”) y manipulaciones avanzadas con Pandas.
- Análisis estadísticos básicos con NumPy y SciPy.
2. Ciencia de datos
La popularidad de la Ciencia de Datos ha crecido de manera exponencial, hecho que podemos confirmar experimentalmente nosotros mismos si acudimos a la web de Google Trends y buscamos el término “data science”. Este interés queda justificado por la actual era de la información en la que vivimos, con compañías que utilizan de manera intensiva las diversas teorías de esta disciplina, como son Google, Facebook, Netflix…
La Ciencia de Datos se describe habitualmente, de manera gráfica, mediante el diagrama de Venn de Drew Conway. No obstante, conceptos como “escepticismo”, “experimentación”, “simulación” o “replicación”, entre otros, también tienen cabida en esta disciplina. En esta misma línea, es recomendable la lectura del artículo “50 years of Data Science” (enlace), de la mano de David Donoho, y en el cual figuran las siguientes seis etapas que componen un proyecto de Ciencia de Datos:
- Exploración y preparación de los datos.
- Representación y transformación de los datos.
- Cálculos utilizando los datos.
- Modelización de los datos.
- Visualización y presentación de los datos.
- “Ciencia” a través de la Ciencia de Datos.
3. Uso de Jupyter en Coursera
Personalmente, como la especialización la seguiré en modo “Audit”, mi objetivo es realizar las tareas, los ejercicios e incluso los cuestionarios localmente, en lugar de a través de las herramientas que ofrece Coursera en la propia plataforma. Para ello, con miras a tener disponible el acceso a los distintos notebooks de Jupyter, he instalado en mi ordenador la última versión de Anaconda (enlace).
4. Funciones en Python
Familiaricémonos un poco con los notebooks de Python.
x = 1
y = 2
x + y
3
Los objetos declarados en una celda, permanecen disponibles para que trabajemos con ellos posteriormente como deseemos.
x
1
Refactoricemos el anterior código en una función que sume dos números:
def sumar_numeros(x, y):
return x + y
sumar_numeros(1, 2)
3
Ejercicio: modifica la anterior función para que acepte tres parámetros, en lugar de dos, y devuelva la suma de todos ellos.
def sumar_numeros(x, y, z):
return x + y + z
sumar_numeros(1, 2, 3)
6
Así definida, la función sumar_numeros() pierde la funcionalidad de sumar únicamente dos números, ya que Python arrojaría un error si solo le pasamos el valor de dos argumentos. Podemos solventar esta situación si el tercer parámetro declarado, z, queda como opcional.
Nota: los parámetros opcionales de una función figuran siempre los últimos en la declaración de esta.
def sumar_numeros(x, y, z=None):
if z == None:
return x + y
else:
return x + y + z
sumar_numeros(1, 2)
3
sumar_numeros(1, 2, 3)
6
Para imprimir múltiples valores, como resultado de una celda en un notebook de Jupyter, podemos recurrir a la función print().
print(sumar_numeros(2, 3))
print(sumar_numeros(2, 3, 4))
5
9
Podemos asignar a variables los valores que una función devuelve.
def sumar_numeros(x, y, z=None, flag=False):
if flag:
print("El valor de flag es verdadero.")
if z == None:
return x + y
else:
return x + y + z
a = sumar_numeros(1, 2)
print(a)
3
b = sumar_numeros(1, 2, 3, True)
print(b)
El valor de flag es verdadero.
6
En ocasiones, puede resultarnos útil que, en la llamada a la función, aparezca el nombre de algunos de sus parámetros (o de todos ellos) junto con el valor asignado, puesto que aporta bastante legibilidad.
c = sumar_numeros(x=1, y=2, z=3, flag=True)
print(c)
El valor de flag es verdadero.
6
Ejercicio: reescribe la siguiente función para que funcione de manera correcta. Esta función debería sumar dos números si el valor del parámetro kind es "add" o si este no se le suministra. En caso contrario, debe restar al primer número el segundo.
def do_math(?, ?, ?):
if (kind=='add'):
return a+b
else:
return a-b
do_math(1, 2)
def do_math(a, b, kind="add"):
if kind == "add":
return a + b
else:
return a - b
do_math(1, 2)
3
5. Tipos y secuencias en Python
5.1. La función type
Con la función type() accedemos al tipo de un objeto:
type("Esto es una cadena de texto.")
str
type(None)
NoneType
type(10)
int
type(3.141592)
float
type(sumar_numeros)
function
Analicemos, a continuación, los tres tipos básicos de colecciones que Python posee: tuplas, listas y diccionarios.
5.2. Tuplas y listas
Por lo que respecta a las tuplas, son objetos inmutables que escribimos entre paréntesis (aunque el uso de estos es opcional si suministramos una serie de objetos separados por comas).
x = (1, "a", True, 3.14)
type(x)
tuple
x = 1, 'a', True, 3.14
type(x)
tuple
Nota: a la hora de declarar cadenas de texto, es indiferente utilizar comillas simples ' o dobles ".
Las listas, a diferencia de las tuplas, son mutables, es decir, está permitido modificar el valor de sus elementos, ampliarlas, reducirlas, etc. Para generar una, utilizamos los corchetes.
x = [1, "a", True, 3.14]
type(x)
list
Podemos añadir elementos a la anterior lista utilizando el método append().
x.append("b")
x.append(1.0)
print(x)
[1, 'a', True, 3.14, 'b', 1.0]
Tanto las listas como las tuplas son objetos iterables que podemos recorrer, por ejemplo, utilizando bucles.
tupla = (1, "a", 3.14, True)
for t in tupla:
print(t)
1
a
3.14
True
lista = [2, 2.0, False, "b"]
for l in lista:
print(l)
2
2.0
False
b
Por otro lado, podemos acceder a los elementos de una tupla o lista a través de su índice, con el operador [] (que viene a ser un atajo para un método get() que posee un objeto de tipo tuple o list). Recordemos aquí que Python comienza a contar índices en cero y que cuando utilizamos números negativos, empezamos desde el último elemento de la colección hacia atrás.
tupla[0]
1
lista[-1]
'b'
A través de este operador, podemos reformular el anterior bucle de tipo for como uno de tipo while.
i = 0
while i != len(tupla):
print(tupla[i])
i += 1
1
a
3.14
True
Podemos realizar “operaciones matemáticas” sobre ambos tipos de objetos. Por ejemplo,
+concatena.*repite.
(1, 2) + (3, 4)
(1, 2, 3, 4)
(1, 2) * 3
(1, 2, 1, 2, 1, 2)
[3, False] + ["a", 1.0]
[3, False, 'a', 1.0]
[3.14] * 4
[3.14, 3.14, 3.14, 3.14]
El operador in (y su contrapartida not in) es de suma utilidad, pues revisa si un elemento pertenece o no a una colección en concreto.
tupla
(1, 'a', 3.14, True)
"Hola" in tupla
False
"a" in tupla
True
lista
[2, 2.0, False, 'b']
2.71 not in lista
True
"b" not in lista
False
En Python, el operador [] puede devolver múltiples valores (técnica que habitualmente se conoce en inglés como slicing).
Como una cadena de texto, en Python, no es más que una lista de caracteres, veamos en acción esta técnica con un sencillo ejemplo.
texto = "Esto es un texto de prueba."
print(texto[0]) # Primer carácter
print(texto[0:1]) # Primer carácter
print(texto[5:10]) # Desde el quinto hasta el décimo, sin llegar a él.
print(texto[4:]) # Desde el cuarto en adelante.
print(texto[:4]) # Desde el principio hasta el cuarto, sin llegar a él.
print(texto[0:15:2]) # Desde el principio hasta el 15, sin llegar a él y de dos en dos.
E
E
es un
es un texto de prueba.
Esto
Et su et
print(texto[-4:-2])
eb
La técnica de slicing es básica a la hora de trabajar con matrices o tablas de datos, como veremos en futuras lecciones.
Ejercicio: ¿cuál es la instrucción adecuada para extraer la palabra Christopher de la cadena de texto declarada en la variable x?
x = 'Dr. Christopher Brooks'
print(x[???])
x = 'Dr. Christopher Brooks'
print(x[4:15])
print(x[-18:-7])
Christopher
Christopher
Como hemos dicho, las cadenas de texto no son más que listas de caracteres, por lo que aquellas operaciones que podemos realizar sobre estas últimas están también disponibles sobre las primeras.
nombre = "Alexis"
apellido = "Sáez"
print(nombre + " " + apellido)
print(nombre * 4)
print("exi" in nombre)
Alexis Sáez
AlexisAlexisAlexisAlexis
True
La función split() separa una cadena de texto en subcadenas:
nombre = "Alexis Sáez".split(' ')[0]
apellido = "Alexis Sáez".split(' ')[-1]
print(nombre)
print(apellido)
Alexis
Sáez
Hemos de prestar atención a los tipos de los objetos cuando estamos realizando operaciones aritméticas con ellos, puesto que algunas combinaciones no están permitidas.
"Alexis" + 2
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-42-599373231bbc> in <module>
----> 1 "Alexis" + 2
TypeError: can only concatenate str (not "int") to str
"Alexis" + str(2)
'Alexis2'
5.3. Diccionarios
Examinemos, finalmente, los diccionarios, que son colecciones no ordenadas de elementos etiquetados, que siguen la sintaxis key : value. Si para las tuplas utilizamos paréntesis y para las lista corchetes, los diccionarios se generan a partir de llaves.
mails = {"Alexis Sáez": "ejemplo1@gmail.com",
"Ana Pérez": "ejemplo2@gmail.com"}
mails["Alexis Sáez"]
'ejemplo1@gmail.com'
Podemos añadir elementos a un diccionario utilizando la técnica de key = value.
mails["Juan Garcia"] = "ejemplo3@gmail.com"
mails["Irene Martínez"] = None
Los diccionarios son elementos iterables que podemos recorrer de diversas formas.
for nombre in mails:
print(nombre)
Alexis Sáez
Ana Pérez
Juan Garcia
Irene Martínez
for nombre in mails.keys():
print(nombre)
Alexis Sáez
Ana Pérez
Juan Garcia
Irene Martínez
for nombre in mails:
print(mails[nombre])
ejemplo1@gmail.com
ejemplo2@gmail.com
ejemplo3@gmail.com
None
for mail in mails.values():
print(mail)
ejemplo1@gmail.com
ejemplo2@gmail.com
ejemplo3@gmail.com
None
for nombre, mail in mails.items(): # Itera sobre keys y values a la vez.
print("Nombre:", nombre, "Mail:", mail)
Nombre: Alexis Sáez Mail: ejemplo1@gmail.com
Nombre: Ana Pérez Mail: ejemplo2@gmail.com
Nombre: Juan Garcia Mail: ejemplo3@gmail.com
Nombre: Irene Martínez Mail: None
Este último ejemplo nos permite presentar una característica importante de Python: el unpacking (“desempaquetado”) de tuplas.
datos = ("Alexis Sáez", "ejemplo1@gmail.com")
nombre, mail = datos
print(nombre)
print(mail)
Alexis Sáez
ejemplo1@gmail.com
Hemos de ser cautos, pues ha de coincidir la cantidad de variables con el total de elementos a “desempacar”.
nombre, mail, tfno = datos
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-53-472adc290c80> in <module>
----> 1 nombre, mail, tfno = datos
ValueError: not enough values to unpack (expected 3, got 2)
6. Cadenas de texto
Python 3, por defecto, utiliza el estándar de codificación Unicode, por lo que no encontraremos dificultades a la hora de trabajar con diversos tipos de caracteres (más allá incluso de los existentes en el alfabeto latino).
Para evitar tener que envolver continuamente datos en la función str(), de cara a generar cadenas de texto, conviene que utilicemos la combinación de marcadores (conocidos como placeholders en inglés), {}, y el método format() asociado a los objetos de tipo str.
ventas = {"precio": 3.14,
"num_objetos": 5,
"nombre": "Alexis"}
texto_factura = "{} compró {} objetos a {} euros cada unidad, ascendiendo el total a {} euros."
print(texto_factura.format(ventas["nombre"],
ventas["num_objetos"],
ventas["precio"],
ventas["precio"] * ventas["num_objetos"]))
Alexis compró 5 objetos a 3.14 euros cada unidad, ascendiendo el total a 15.700000000000001 euros.
El método format() permite casi una miríada de posibilidades de configuración, tal como reza en la página de documentación asociada.
7. Lectura de archivos CSV
Los archivos CSV (del inglés comma-separated values) son un tipo de documento en formato abierto sencillo para representar datos en forma de tabla, en las que las columnas se separan por comas (o punto y coma en donde la coma es el separador decimal: Chile, Perú, Argentina, España, Brasil…) y las filas por saltos de línea. (Fuente)
Para la lectura de este tipo de ficheros, utilizaremos la librería de Python csv, que hemos de importar para poder tener acceso a las funciones contenidas en ella.
import csv
A continuación, y para lo que resta de módulo, establezcamos la precisión de los números de tipo float a 2 en este notebook. Para ello, tecleamos
%precision 2
'%.2f'
Este tipo de instrucciones, cuyo rango de aplicación únicamente comprende los notebooks de Jupyter, se conocen como magic commands y su documentación asociada la podemos encontrar siguiendo este enlace. Por otro lado, nos resultará sumamente útil la lectura de este artículo donde nos ofrecen consejos, atajos y orientaciones varias a la hora de trabajar con esta herramienta.
Procedamos, pues, a la lectura del archivo mpg.csv (ubicado en la carpeta data), conviertiéndolo en una lista de diccionarios. Junto con el conjunto de datos Iris, es uno de los ejemplos clásicos con los que se suele comenzar a trabajar, de manera práctica, en Ciencia de Datos.
with open("data/mpg.csv") as csvfile:
mpg = list(csv.DictReader(csvfile))
mpg[:3] # Primeros tres diccionarios (es decir, coches)
[OrderedDict([('', '1'),
('manufacturer', 'audi'),
('model', 'a4'),
('displ', '1.8'),
('year', '1999'),
('cyl', '4'),
('trans', 'auto(l5)'),
('drv', 'f'),
('cty', '18'),
('hwy', '29'),
('fl', 'p'),
('class', 'compact')]),
OrderedDict([('', '2'),
('manufacturer', 'audi'),
('model', 'a4'),
('displ', '1.8'),
('year', '1999'),
('cyl', '4'),
('trans', 'manual(m5)'),
('drv', 'f'),
('cty', '21'),
('hwy', '29'),
('fl', 'p'),
('class', 'compact')]),
OrderedDict([('', '3'),
('manufacturer', 'audi'),
('model', 'a4'),
('displ', '2'),
('year', '2008'),
('cyl', '4'),
('trans', 'manual(m6)'),
('drv', 'f'),
('cty', '20'),
('hwy', '31'),
('fl', 'p'),
('class', 'compact')])]
El archivo mpg.csv contiene datos sobre el consumo de combustible de 234 coches, siendo las características registradas de estos las que se muestran a continuación:
mpg: millas por galón.class: clasificación del coche.cty: millas por galón en ciudad.cyl: número de cilindros del coche.displ: desplazamiento del motor del coche en litros.drv: tipo de tracción del coche (f = delantera, r = trasera, 4 = cuatro por cuatro).fl: tipo de combustible del coche (e = etanol E85, d = diesel, r = regular, p = premium, c = CNG).hwy: millas por galón en autopista.manufacturer: fabricante del coche.model: modelo del cochetrans: tipo de transmisión del coche.year: año del modelo del coche.
len(mpg) # Total de coches
234
Es decir, tenemos un diccionario por cada uno de los 234 coches existentes en el fichero mpg.csv.
Acto seguido, podemos acceder a las propiedades registradas a través del método keys() del diccionario.
mpg[0].keys()
odict_keys(['', 'manufacturer', 'model', 'displ', 'year', 'cyl', 'trans', 'drv', 'cty', 'hwy', 'fl', 'class'])
Calculemos el consumo medio de millas por galón en ciudad de todos los coches.
Nota: todos los valores son cadenas de texto, por lo que hemos de ser cautos a la hora de utilizar operaciones aritméticas entre ellos. En esta ocasión, la función float() resulta de gran utilidad.
consumo = 0
for coche in mpg:
consumo += float(coche["cty"])
media = consumo / len(mpg)
print(media)
16.858974358974358
El anterior bloque de código puede ser expresado en una única línea gracias a las comprensiones de listas (list comprehensions):
sum(float(coche["cty"]) for coche in mpg) / len(mpg)
16.86
Para reforzar la anterior construcción, veamos el caso de la media de millas por galón en autopista, el código sería:
sum(float(coche["hwy"]) for coche in mpg) / len(mpg)
23.44
Dado un galón de combustible, se recorren más millas en autopista que en ciudad, conclusión lógica desde el punto de vista del sentido común.
A continuación, compliquemos un poco más las consultas que estamos realizando al conjunto de datos mpg. Busquemos ahora el consumo medio de millas por galón en ciudad, pero desagregado en función del número de cilindros que posee un coche.
En primer lugar, obtengamos un conjunto con los valores disponibles para el número de cilindros, para lo cual la función set() resulta de gran ayuda.
cilindros = set(coche["cyl"] for coche in mpg)
cilindros
{'4', '5', '6', '8'}
Es decir, tenemos coches en nuestro conjunto de datos con 4, 5, 6 u 8 cilindros.
Ahora, almacenemos en una lista las cuatro medias que nos interesan. Para cada valor del conjunto de cilindros, recorreremos el conjunto de diccionarios y, en caso de coincidir el valor de un coche con el de interés, procederemos a realizar los cálculos oportunos.
mpg_cty_cilindro = []
for cilindro in cilindros: # Iteramos sobre los distintos números de cilindros
suma_mpg = 0
total_coches_cilindro = 0
for coche in mpg: # Iteramos sobre todos los diccionarios
if coche['cyl'] == cilindro: # Si el número de cilindros coincide
suma_mpg += float(coche['cty']) # suma mpg
total_coches_cilindro += 1 # incrementa el contador
mpg_cty_cilindro.append((cilindro, suma_mpg / total_coches_cilindro)) # añade la tupla ('cilindro', 'mpg medio')
mpg_cty_cilindro.sort(key=lambda x: x[0]) # ordena por cilindros de menor a mayor
mpg_cty_cilindro
[('4', 21.01), ('5', 20.50), ('6', 16.22), ('8', 12.57)]
Hemos empleado una función lambda o anónima, que es un tipo especial de funciones que estudiaremos en una lección posterior.
A medida que el número de cilindros crece, las millas por galón en ciudad decrecen.
Estudiemos un ejemplo similar para reforzar las líneas de código vistas en el anterior: busquemos la media de millas por galón en autovía para las diferentes clases de coches.
clases_coches = set(coche['class'] for coche in mpg)
clases_coches
{'2seater', 'compact', 'midsize', 'minivan', 'pickup', 'subcompact', 'suv'}
mpg_hwy_clase = []
for clase in clases_coches:
suma_mpg = 0
total_coches_clase = 0
for coche in mpg:
if coche['class'] == clase:
suma_mpg += float(coche['hwy'])
total_coches_clase += 1
mpg_hwy_clase.append((clase, suma_mpg / total_coches_clase))
mpg_hwy_clase.sort(key=lambda x: x[1])
mpg_hwy_clase
[('pickup', 16.88),
('suv', 18.13),
('minivan', 22.36),
('2seater', 24.80),
('midsize', 27.29),
('subcompact', 28.14),
('compact', 28.30)]
A primera vista, el proceso para llevar a cabo los análisis presentados es un tanto complejo y tedioso de realizar. Veremos, en el próximo módulo, que la librería pandas agilizará todos estos procedimientos.
8. Fechas y horas en Python
En ocasiones, a la hora de llevar a cabo de análisis de datos, hemos de trabajar con fechas y horas. Por ejemplo, si buscamos el período de mayor ventas durante una etapa determinada o la hora de mayor actividad, por parte de los usuarios, en un foro de Internet.
En Python, las librerías habituales para trabajar con fechas y horas son datetime y time.
import datetime as dt
import time as tm
La función time() devuelve el número de segundos transcurridos desde el uno de enero de 1970 (Epoch).
tm.time()
1559035984.46
Obviamente, no resulta especialmente cómodo trabajar unidades de tiempo de esta manera. No obstante, si nos proporcionan datos codificados de esta forma, podemos convertirlos en fechas y horas más manejables utilizando la función fromtimestamp() del módulo datetime.
dtnow = dt.datetime.fromtimestamp(tm.time())
dtnow
datetime.datetime(2019, 5, 28, 11, 33, 4, 627060)
Como podíamos sospechar, la variable generada, dtnow, posee atributos de gran utilidad a la hora de trabajar con fechas y horas.
dtnow.year, dtnow.month, dtnow.day, dtnow.hour, dtnow.minute, dtnow.second # extrae año, mes, día... de una fecha
(2019, 5, 28, 11, 33, 4)
Nota técnica: cuando en Python separamos variables por una coma, aunque no estemos utilizando paréntesis, implícitamente estamos generando una tupla.
La función timedelta() nos posibilita realizar operaciones aritméticas y comparaciones entre fechas y horas.
delta = dt.timedelta(days = 100) # crea una diferencia delta de 100 días
delta
datetime.timedelta(days=100)
La anterior función mostrada se utiliza habitualmente para crear períodos de interés a la hora de estudiar conjuntos de datos. Por ejemplo:
today = dt.date.today()
today - delta
datetime.date(2019, 2, 17)
Finalmente, la librería datetime nos permite fácilmente llevar a cabo comparaciones entre fechas y horas.
today > today - delta # comparación entre fechas
True
9. Python avanzado: objetos y map()
9.1 Objetos
Aunque, a lo largo de la especialización, rara vez nos veremos en la tesitura de generar clases propias, refresquemos su creación en Python elaborando una que modelice personas:
class Persona:
departamento = "Departamento de Educación" # Variable que comparten todos los objetos instanciados de la clase
def set_nombre(self, nombre): # ejemplo de método
self.nombre = nombre
def set_localizacion(self, localizacion):
self.localizacion = localizacion
Instanciemos la clase:
alexis = Persona()
alexis.set_nombre("Alexis Sáez")
alexis.set_localizacion("Ibi (Alicante, España)")
print("{} vive en {} y trabaja en el {}.".format(alexis.nombre, alexis.localizacion, alexis.departamento))
Alexis Sáez vive en Ibi (Alicante, España) y trabaja en el Departamento de Educación.
9.2 map()
Acto seguido, supongamos que tenemos acceso a los precios para cuatro productos que ofrecen dos tiendas diferentes. Nuestro objetivo es averiguar a cuánto ascenderá el desembolso total, si buscamos adquirir dichos cuatro productos, de manera que paguemos la menor cantidad monetaria para cada uno de ellos. Dadas ambas listas de precios, dicho tipo de comparaciones elemento a elemento se pueden llevar a cabo a través de la función map(), que aplica una determinada función a una serie de objetos iterables.
tienda1 = [10.00, 11.00, 12.34, 2.34]
tienda2 = [9.00, 11.10, 12.34, 2.01]
precio_mas_barato = map(min, tienda1, tienda2)
precio_mas_barato # lazy evaluation
<map at 0x1288ced92e8>
Python, de hecho, no calcula mínimo alguno cuando creamos la variable precio_mas_barato, sino que espera hasta el momento que procedemos a iterar sobre este objeto de tipo map. Esta manera de actuar se conoce como lazy evaluation y nos permite una gestión eficiente de la memoria.
for precio in precio_mas_barato:
print(precio)
9.0
11.0
12.34
2.01
desembolso = sum(list(map(min, tienda1, tienda2)))
desembolso
34.35
Ejercicio: dada la siguiente lista de profesores de la especialización, escribe una función y utilízala combinada con map() para extraer tanto el título de cada persona como su apellido (por ejemplo, ['Dr. Brooks', 'Dr. Collins-Thompson', …]).
people = ['Dr. Christopher Brooks', 'Dr. Kevyn Collins-Thompson', 'Dr. VG Vinod Vydiswaran', 'Dr. Daniel Romero']
def split_title_and_name(person):
return #Your answer here
list(map(#Your answer here))
people = ['Dr. Christopher Brooks',
'Dr. Kevyn Collins-Thompson',
'Dr. VG Vinod Vydiswaran',
'Dr. Daniel Romero']
def split_title_and_name(person):
separated_name = person.split(" ")
return "{} {}".format(separated_name[0], separated_name[-1])
list(map(split_title_and_name, people))
['Dr. Brooks', 'Dr. Collins-Thompson', 'Dr. Vydiswaran', 'Dr. Romero']
10. Python avanzado: lambdas y comprensiones de listas
10.1 Lambdas
La palabra clave lambda nos permite crear funciones anónimas en Python (conocidas comúnmente en este lenguaje de programación como lambdas). Suelen ser funciones cortas, que podemos escribir generalmente en una línea (una única expresión, sin valores para parámetros opciones ni una lógica compleja en su interior) y mediante la instrucción lambda no nos vemos en la necesidad de haber de crear una función con nombre para desempeñar cierta tarea concreta.
Veamos un ejemplo de una función lambda que toma tres parámetros y suma los primeros dos.
suma_dos = lambda a, b, c: a + b
suma_dos(1, 2, 3)
3
suma_dos(3, 2, 1)
5
Ejercicio: convierte la siguiente función en una anónima o lambda:
people = ['Dr. Christopher Brooks', 'Dr. Kevyn Collins-Thompson', 'Dr. VG Vinod Vydiswaran', 'Dr. Daniel Romero']
def split_title_and_name(person):
return person.split()[0] + ' ' + person.split()[-1]
#option 1
for person in people:
print(split_title_and_name(person) == (lambda person:???))
#option 2
#list(map(split_title_and_name, people)) == list(map(???))
people = ['Dr. Christopher Brooks',
'Dr. Kevyn Collins-Thompson',
'Dr. VG Vinod Vydiswaran',
'Dr. Daniel Romero']
def split_title_and_name(person):
return person.split()[0] + ' ' + person.split()[-1]
# Opción 1
for person in people:
print(split_title_and_name(person) == (lambda p: p.split()[0] + ' ' + p.split()[-1])(person))
# Opción 2
list(map(split_title_and_name, people)) == list(map(lambda person: person.split()[0] + ' ' + person.split()[-1], people))
True
True
True
True
True
10.2 Comprensiones de listas
A continuación, almacenemos en una lista los números pares menores que mil:
lista_pares = []
for i in range(1000):
if i % 2 == 0:
lista_pares.append(i)
print(lista_pares[:50]) # Primeros cincuenta pares
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98]
Mediante las comprensiones de listas podemos conseguir el mismo objetivo con un menor número de líneas de código, expresando el bucle y la estructura condicional de una forma mucho más compacta (que también tiende a ser más rápida y eficiente):
lista_pares = [i for i in range(1000) if i % 2 == 0]
print(lista_pares[:50]) # Primeros 50 pares
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98]
Ejercicio: convierte la siguiente función en una comprensión de lista:
def times_tables():
lst = []
for i in range(10):
for j in range (10):
lst.append(i*j)
return lst
times_tables() == [???]
def times_tables():
lst = []
for i in range(10):
for j in range (10):
lst.append(i*j)
return lst
times_tables() == [i * j for i in range(10) for j in range(10)]
True
Ejercicio: muchas organizaciones poseen identificadores de usuario que están restringidas en cierta manera. Supón que trabajas para un proveedor de internet y dichos identificadores están formados por dos letras seguiidas de dos números (por ejemplo, aa49). Tu tarea en la empresa podría ser mantener un registro de la facturación para cada posible usuario.
Escribe una comprensión de lista que genere todos los posibles identificadores de usuario. Supón que las letras son únicamente minúsculas.
lowercase = 'abcdefghijklmnopqrstuvwxyz'
digits = '0123456789'
answer = [???]
correct_answer == answer
lowercase = 'abcdefghijklmnopqrstuvwxyz'
digits = '0123456789'
answer = [i + j + k + l for i in lowercase for j in lowercase for k in digits for l in digits]
print(answer[:50]) # Primeros 50 identificadores
['aa00', 'aa01', 'aa02', 'aa03', 'aa04', 'aa05', 'aa06', 'aa07', 'aa08', 'aa09', 'aa10', 'aa11', 'aa12', 'aa13', 'aa14', 'aa15', 'aa16', 'aa17', 'aa18', 'aa19', 'aa20', 'aa21', 'aa22', 'aa23', 'aa24', 'aa25', 'aa26', 'aa27', 'aa28', 'aa29', 'aa30', 'aa31', 'aa32', 'aa33', 'aa34', 'aa35', 'aa36', 'aa37', 'aa38', 'aa39', 'aa40', 'aa41', 'aa42', 'aa43', 'aa44', 'aa45', 'aa46', 'aa47', 'aa48', 'aa49']
11. La librería NumPy
Adentrémonos, en este apartado, en los entresijos de la librería NumPy. Sobre este módulo se asienta el ecosistema que permite trabajar Ciencia de Datos en Python, ya que posibilita el cálculo con arrays y matrices de una manera eficiente en este lenguaje de programación.
import numpy as np
11.1 Creando arrays
A continuación, generemos nuestro primer array con NumPy. Para ello, podemos crear una lista y convertirla a dicha estructura:
mi_lista = [1, 2, 3]
x = np.array(mi_lista)
x
array([1, 2, 3])
También podemos construir arrays pasando como argumento una lista a la función array():
x = np.array([1, 2, 3])
x
array([1, 2, 3])
De manera similar, generamos arrays multidimensionales a partir de una lista de listas como argumento de la función array():
m = np.array([[1, 2, 3], [4, 5, 6]])
m
array([[1, 2, 3],
[4, 5, 6]])
El atributo shape, de un objeto de tipo array de NumPy, devuelve las dimensiones (filas y columnas) del array generado:
x.shape
(3,)
m.shape
(2, 3)
La función reshape() permite modificar las dimensiones de array determinado:
m.reshape(3, 2)
array([[1, 2],
[3, 4],
[5, 6]])
La función arange() devuelve valores equiespaciados en un intervalo dado:
n = np.arange(0, 30, 2) # empieza en 0, de 2 en 2, hasta 29
n
array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28])
n = np.arange(1, 47, 5)
n
array([ 1, 6, 11, 16, 21, 26, 31, 36, 41, 46])
En cambio, si dado un intervalo queremos generar en su interior una serie de puntos equiespaciados, la función a utilizar es linspace():
o = np.linspace(0, 4, 9) # devuelve 9 valores equiespaciados entre 0 y 4
o
array([0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. ])
o.reshape(3, 3)
array([[0. , 0.5, 1. ],
[1.5, 2. , 2.5],
[3. , 3.5, 4. ]])
Existen una serie de funciones especiales para generar arrays con una estructura particular:
ones(): array de unos.zeros(): array de ceros.eye(): matriz unidad.diag(): matriz diagonal a partir de un array.
np.ones((4, 5))
array([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
np.zeros((3, 4))
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
np.eye(5)
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
np.diag(np.array([1, 2, 3, 4]))
array([[1, 0, 0, 0],
[0, 2, 0, 0],
[0, 0, 3, 0],
[0, 0, 0, 4]])
El operador * o la función repeat() nos permiten repetir una lista, pero hay sutiles matices en su funcionamiento, como apreciamos acto seguido:
np.array([1, 2, 3] * 3)
array([1, 2, 3, 1, 2, 3, 1, 2, 3])
np.repeat(np.array([1, 2, 3]), 3)
array([1, 1, 1, 2, 2, 2, 3, 3, 3])
11.2 Combinando arrays
Por otro lado, podemos construir nuevos arrays combinando unos existentes.
p = np.ones([2, 3], int)
p
array([[1, 1, 1],
[1, 1, 1]])
Con la función vstack() apilamos arrays verticalmente (por filas):
np.vstack([p, 2*p])
array([[1, 1, 1],
[1, 1, 1],
[2, 2, 2],
[2, 2, 2]])
Mientras que la función hstack() hace lo propio horizontalmente (por columnas):
np.hstack([p, 2*p])
array([[1, 1, 1, 2, 2, 2],
[1, 1, 1, 2, 2, 2]])
11.3 Operaciones
Los operadores aritméticos realizan las opciones elemento a elemento:
x = np.array([1, 2, 3])
y = np.array([4, 5, 6])
x + y
array([5, 7, 9])
x - y
array([-3, -3, -3])
x * y
array([ 4, 10, 18])
x / y
array([0.25, 0.4 , 0.5 ])
x ** 2
array([1, 4, 9], dtype=int32)
Para calcular el producto escalar, hemos de utilizar la función dot():
x.dot(y)
32
El atributo .T realiza la transposición de un array
z = np.array([y, y**2])
z
array([[ 4, 5, 6],
[16, 25, 36]])
z.shape
(2, 3)
z.T
array([[ 4, 16],
[ 5, 25],
[ 6, 36]])
z.T.shape
(3, 2)
Finalmente, el atributo .dtype nos indica el tipo de variable en que está almacenado un array, que podemos modificar mediante la función astype().
z.dtype
dtype('int32')
z = z.astype("f")
z.dtype
dtype('float32')
11.4 Funciones matemáticas
La librería NumPy incorpora de base algunas conocidas funciones matemáticas.
a = np.array([-4, -2, 1, 3, 5])
a
array([-4, -2, 1, 3, 5])
a.sum()
3
a.max()
5
a.argmax() # posición del máximo
4
a.min()
-4
a.argmin() # posición del mínimo
0
a.mean()
0.6
a.std()
3.2619012860600183
11.5 Extracción de elementos (indexing & slicing)
A continuación, veamos qué posibilidades nos ofrece NumPy de cara a la extracción de elementos de un array.
s = np.arange(13) ** 2
s
array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144],
dtype=int32)
Con el operador [] accedemos, al igual que cuando utilizamos otro tipo de colecciones, al elemento ubicado en un índice concreto.
s[0], s[4], s[-1]
(0, 16, 144)
Mediante el operador : extraemos múltiples elementos de un array de manera simultánea, tal y como estamos acostumbrados a utilizar dicho operador.
s[0:4]
array([0, 1, 4, 9], dtype=int32)
s[:3]
array([0, 1, 4], dtype=int32)
s[2:8:2]
array([ 4, 16, 36], dtype=int32)
s[-5::-2]
array([64, 36, 16, 4, 0], dtype=int32)
Podemos extender el uso de esta notación a arrays multidimensionales.
r = np.arange(36)
r.resize((6, 6))
r
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])
r[2, 2]
14
r[3, 3:6]
array([21, 22, 23])
r[:2, :-1]
array([[ 0, 1, 2, 3, 4],
[ 6, 7, 8, 9, 10]])
r[-1, ::2]
array([30, 32, 34])
También podemos realizar operaciones de filtrado utilizando condiciones lógicas (en este punto nos puede interesar ver también la función where()).
r[r > 30]
array([31, 32, 33, 34, 35])
r[r > 30] = 30
r
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 30, 30, 30, 30, 30]])
11.6 Copiando datos
Hemos de ser cautos a la hora de copiar y modificar arrays en NumPy.
r2 = r[:3, :3]
r2
array([[ 0, 1, 2],
[ 6, 7, 8],
[12, 13, 14]])
r2[:] = 0
r2
array([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
¡Pero r también ha cambiado!
r
array([[ 0, 0, 0, 3, 4, 5],
[ 0, 0, 0, 9, 10, 11],
[ 0, 0, 0, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 30, 30, 30, 30, 30]])
Para evitar este comportamiento, conviene que utilicemos la función copy().
r_copy = r.copy()
r_copy
array([[ 0, 0, 0, 3, 4, 5],
[ 0, 0, 0, 9, 10, 11],
[ 0, 0, 0, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 30, 30, 30, 30, 30]])
r_copy[:] = 10
r_copy
array([[10, 10, 10, 10, 10, 10],
[10, 10, 10, 10, 10, 10],
[10, 10, 10, 10, 10, 10],
[10, 10, 10, 10, 10, 10],
[10, 10, 10, 10, 10, 10],
[10, 10, 10, 10, 10, 10]])
No obstante, ahora r no ha sido modificado por las operaciones realizadas sobre r_copy.
r
array([[ 0, 0, 0, 3, 4, 5],
[ 0, 0, 0, 9, 10, 11],
[ 0, 0, 0, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 30, 30, 30, 30, 30]])
Ejercicio: Para el siguiente código, ¿qué opción recoge la salida correcta?
old = np.array([[1, 1, 1],
[1, 1, 1]])
new = old
new[0, :2] = 0
print(old)
Opción 1:
[[0 1 1]
[1 1 1]]
Opción 2:
[[1 1 1]
[0 1 1]]
Opción 3:
[[0 0 1]
[1 1 1]]
Opción 4:
[[1 1 1]
[1 1 1]]
Como no hemos usado el método copy(), cualquier modificación sobre la variable new afecta a la variable old. Con la instrucción new[0, :2] = 0 hacemos ceros los dos primeros elementos de la fila superior del array new y, por tanto, de old también. Así pues, la opción acertada es la 3. Comprobémoslo:
old = np.array([[1, 1, 1],
[1, 1, 1]])
new = old
new[0, :2] = 0
print(old)
[[0 0 1]
[1 1 1]]
Ejercicio: Para el siguiente código, ¿qué opción recoge la salida correcta?
old = np.array([[1, 1, 1],
[1, 1, 1]])
new = old.copy()
new[:, 0] = 0
print(old)
Opción 1
[[0 1 1]
[0 1 1]]
Opción 2
[[0 1 1]
[1 1 1]]
Opción 3
[[0 0 0]
[1 1 1]]
Opción 4
[[1 1 1]
[1 1 1]]
En esta ocasión, al emplear la función copy(), los cambios sobre la variable new no afectan a la variable old. Por tanto, la opción correcta es la 4. Comprobémoslo:
old = np.array([[1, 1, 1],
[1, 1, 1]])
new = old.copy()
new[:, 0] = 0
print(old)
[[1 1 1]
[1 1 1]]
11.7 Iterando sobre arrays
Finalmente, estudiemos cómo iterar sobre arrays:
matriz_aleatorios = np.random.randint(0, 10, (4,3))
matriz_aleatorios
array([[8, 9, 8],
[9, 5, 2],
[2, 4, 6],
[0, 0, 7]])
Por ejemplo, podemos iterar por filas de una manera sencilla:
for fila in matriz_aleatorios:
print(fila)
[8 9 8]
[9 5 2]
[2 4 6]
[0 0 7]
Asimismo, es posible iterar por el índice de la fila utilizando la función len():
len(matriz_aleatorios)
4
for i in range(len(matriz_aleatorios)):
print(matriz_aleatorios[i])
[8 9 8]
[9 5 2]
[2 4 6]
[0 0 7]
La función enumerate() nos posibilita combinar los dos anteriores métodos:
for i, fila in enumerate(matriz_aleatorios):
print("La fila", i, "es", fila)
La fila 0 es [8 9 8]
La fila 1 es [9 5 2]
La fila 2 es [2 4 6]
La fila 3 es [0 0 7]
Para acabar, también podemos utiliza la función zip() para iterar sobre varios objetos iterables:
matriz_aleatorios_cuadrado = matriz_aleatorios ** 2
matriz_aleatorios_cuadrado
array([[64, 81, 64],
[81, 25, 4],
[ 4, 16, 36],
[ 0, 0, 49]], dtype=int32)
for i, j in zip(matriz_aleatorios, matriz_aleatorios_cuadrado):
print(i, "+", j, "=", i + j)
[8 9 8] + [64 81 64] = [72 90 72]
[9 5 2] + [81 25 4] = [90 30 6]
[2 4 6] + [ 4 16 36] = [ 6 20 42]
[0 0 7] + [ 0 0 49] = [ 0 0 56]
12. Cuestionario
Dado que estoy siguiendo la especialización en modo Audit, no tengo acceso a la posibilidad de verificar las respuestas que proporciono en los cuestionarios, así como sospecho que tampoco podré hacer lo propio con las prácticas de programación.
No obstante, comparto las respuestas que plantearía a las preguntas que proponen.
Question 1: Python is an example of an
- (a) Interpreted language
- (b) Declarative language
- (c) Operating system language
- (d) Data science language
- (e) Low level language
Respuesta: (a)
Question 2: Data Science is a
- (a) Branch of statistics
- (b) Branch of computer science
- (c) Branch of artificial intelligence
- (d) Interdisciplinary, made up of all of the above
Respuesta: (d)
Question 3: Data visualization is not a part of data science.
- (a) True
- (b) False
Respuesta: (b)
Question 4: Which bracketing style does Python use for tuples?
- (a)
{ } - (b)
( ) - (c)
[ ]
Respuesta: (b)
Question 5: In Python, strings are considered Mutable, and can be changed.
- (a) False
- (b) True
Respuesta: (a)
Esta pregunta me ha resultado interesante, porque creo no se ha llegado a comentar nada al respecto en los vídeos teóricos. Veamos con un sencillo ejemplo que no podemos modificar parte de una cadena de caracteres:
texto = "Esto es una prueba"
texto[0]
'E'
texto[0] = "N"
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-161-1659680a19da> in <module>
----> 1 texto[0] = "N"
TypeError: 'str' object does not support item assignment
No obstante, en cualquier momento podemos hacer que la variable texto apunte a una cadena de caracteres distinta a la dada:
texto = "Segunda prueba"
texto
'Segunda prueba'
Question 6: What is the result of the following code:
['a', 'b', 'c'] + [1, 2, 3]
- (a)
['a', 'b', 'c', 1, 2, 3] - (b)
TypeError: Cannot convert list(int) to list(str) - (c)
['a1', 'b2', 'c3'] - (d)
[['a', 'b', 'c'], [1, 2, 3]]
Respuesta: (a), el operador + concatena listas y en Python estas pueden contener elementos de diversos tipos.
['a', 'b', 'c'] + [1, 2, 3]
['a', 'b', 'c', 1, 2, 3]
Question 7: String slicing is
- (a) A way to make string mutable in python
- (b) A way to reduce the size on disk of strings in python
- (c) A way to make a substring of a string in python
Respuesta: (c)
Question 8: When you create a lambda, what type is returned? E.g. type(lambda x: x+1) returns
- (a)
<class 'function'> - (b)
<class 'type'> - (c)
<class 'int'> - (d)
<class 'lambda'>
Respuesta: (a)
type(lambda x: x+1)
function
Question 9: The epoch refers to
- (a) January 1, year 0
- (b) January 1, year 1970
- (c) January 1, year 1980
- (d) January 1, year 2000
Respuesta: (b)
Question 10: This code, [x**2 for x in range(10)] , is an example of a
- (a) List comprehension
- (b) Sequence comprehension
- (c) Tuple comprehension
- (d) List multiplication
Respuesta: (a)
Question 11: Given a 6x6 NumPy array r, which of the following options would slice the shaded elements?
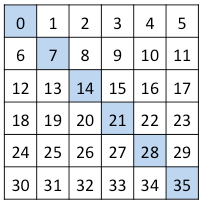
- (a)
r[:, ::7] - (b)
r[0:6, ::-7] - (c)
r[::7] - (d)
r.reshape(36)[::7]
Respuesta (d)
r = np.arange(36).reshape(6, 6)
r
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])
r.reshape(36)[::7]
array([ 0, 7, 14, 21, 28, 35])
Question 12: Given a 6x6 NumPy array r, which of the following options would slice the shaded elements?
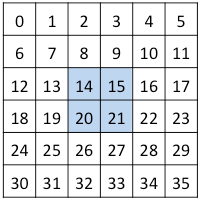
- (a)
r[::2, ::2] - (b)
r[2::2, 2::2] - (c)
r[2:4, 2:4] - (d)
r[[2, 3], [2, 3]]
Respuesta: (c)
r[2:4, 2:4]
array([[14, 15],
[20, 21]])